ConsensusStore¶
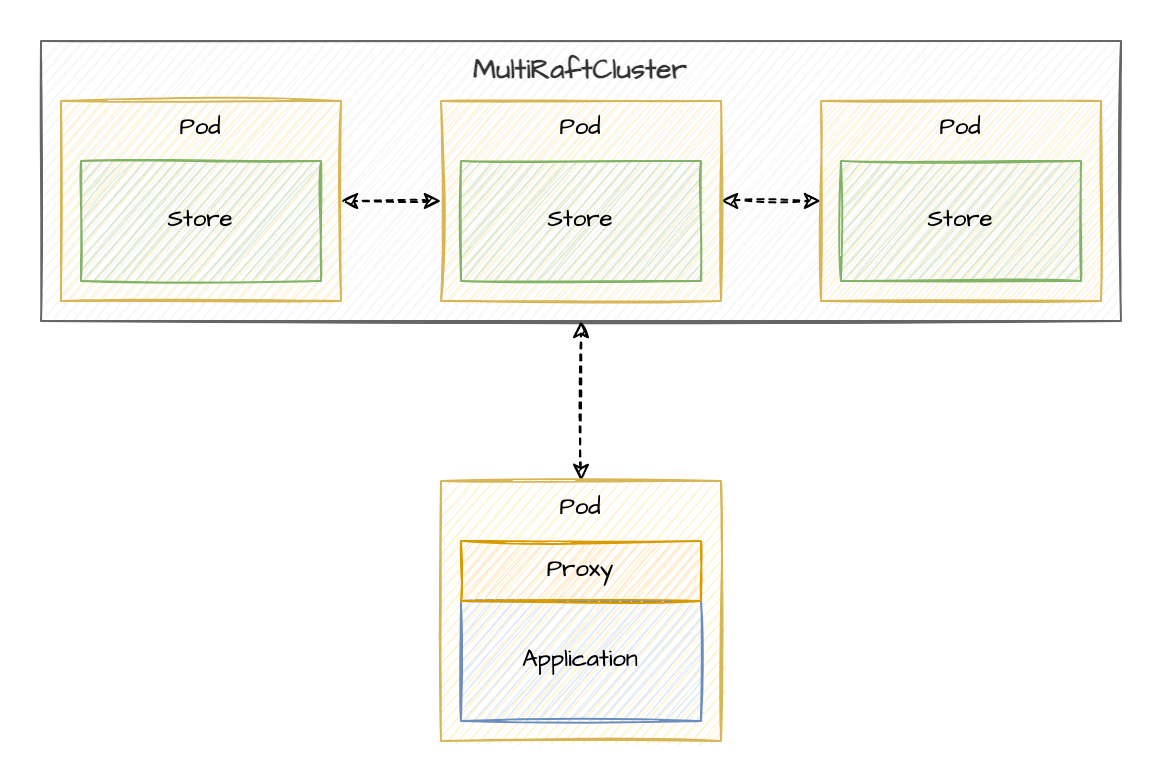
The ConsensusStore is a replicated, fault-tolerant, strongly consistent data store suitable for managing configuration and coordination in distributed applications. The ConsensusStore is implemented as a multi-raft cluster using Dragonboat.
apiVersion: consensus.atomix.io/v1beta1
kind: ConsensusStore
metadata:
name: my-consensus-store
spec:
replicas: 3
groups: 30
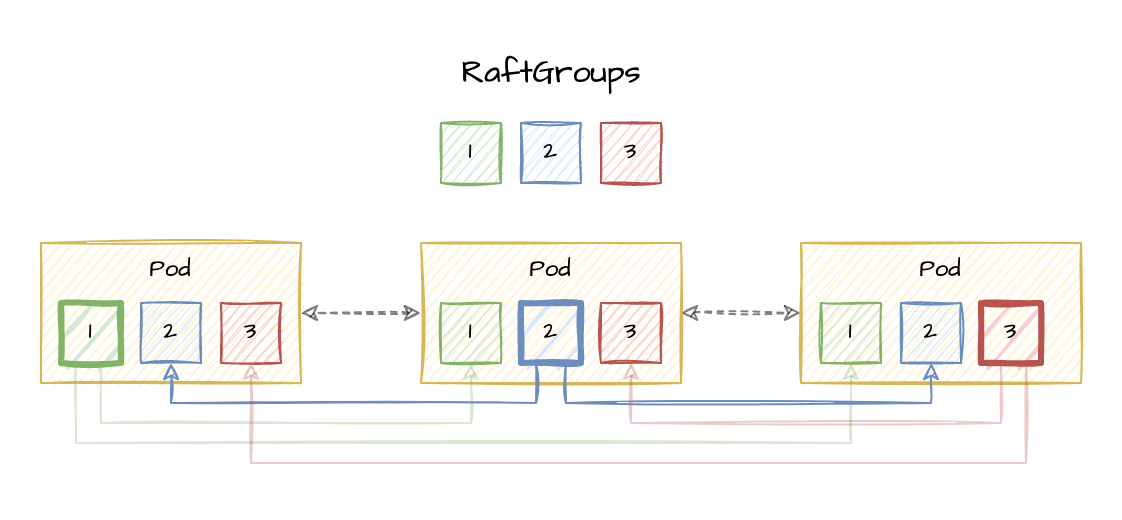
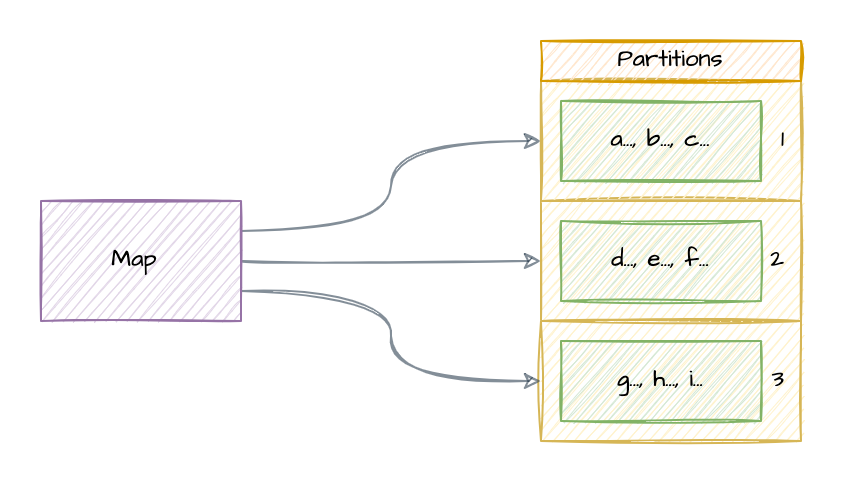
The two most essential fields in the spec are replicas and groups. The replicas field indicates the number of replicas to deploy for the store, and the groups field indicates the number of Raft groups to bootstrap in the cluster. Primitives stored in the ConsensusStore will be partitioned across the Raft groups when possible to scale throughput (primitives with discrete values like Lock, LeaderElection, and Counter, or primitives with strict ordering requirements like List and IndexedMap, usually cannot be partitioned).

Raft works by writing changes to a log on disk. It is strongly recommended that you enable persistence for the Raft logs and snapshots by providing a persistent volume. Raft does not guarantee strong consistency unless logs and snapshots are persisted to stable storage.
apiVersion: consensus.atomix.io/v1beta1
kind: ConsensusStore
metadata:
name: my-consensus-store
spec:
volumeClaimTemplate:
storageClass: "standard"
Monitoring and Debugging the ConsensusStore¶
Underlying the ConsensusStore are several additional custom resources that monitor and manage the Multi-Raft protocol, each Raft group, and the members of each group. Kubernetes tools like kubectl can be used to inspect the Raft cluster state by querying these custom resources.
MultiRaftClusterRaftGroupRaftMember